Crawling-Fehler in der Google Search Console – Was zu tun ist
Soft 404, Server-Fehler, Nicht gefunden – zu all diesen URL-Fehler-Typen findest du in Googles Search Console immer aktuelle Informationen, wenn dem Googlebot beim Crawlen deiner Seite etwas aufgefallen ist. Doch was bedeuten diese Fehler und wie behebst du sie am besten? Im folgenden Artikel geben wir dir eine Anleitung an die Hand, wie du am besten mit Crawling-Fehlern umgehst.
Nutzung des Crawling-Fehler-Berichts in der Search Console
Wie schon in anderen Artikeln beschrieben, besucht Google deine Webseiten regelmäßig um aktuelle Inhalte abzurufen und zu schauen, ob und was sich geändert hat. Beim Crawling der Seiten fällt Google natürlich auf, wenn Inkonsistenzen bestehen. Diese Inkonsistenzen können z.B. durch Verlinkung nicht existenter Inhalte, Downtimes des Servers, mangelnde Zugriffsrechte und weitere Eskapaden entstehen. In der Summe nennt sich die Fehlerfamilie dann Crawling-Fehler.
Google bietet mit der Search Console (ehemals Webmaster Tools) ein mächtiges Tool für Webseitenbetreiber an. Unter anderem wird erst durch die Search Console ein wenig Transparenz in die Crawling-Prozesse gebracht. Es handelt sich dabei jedoch nur um einen Überblick. Noch detailliertere Informationen lassen sich mithilfe einer Logfile Analyse ermitteln, die aber aufwendig ist.
In Crawling-Bericht der Search Console werden dir Größen wie Pro Tag gecrawlte Seiten, Pro Tag heruntergeladenes Datenvolumen und Downloadzeit der Seiten ausgegeben. Diese Größen allein sind in den meisten Fällen noch wenig aussagekräftig. Allerdings bekommen die Kurven meist dann Bedeutung, wenn du sie mit anderen Größen kombinierst. Weiterhin gibt dir Google detaillierten Aufschluss über Fehler, welche dem Googlebot während des Crawlingvorganges aufgefallen sind. Der Crawling-Fehler-Bericht unterteilt sich in zwei Hauptbereiche:
Im Bereich Website-Fehler werden dir die Hauptprobleme angezeigt, die dem Googlebot in den letzten 90 Tagen aufgefallen sind und aufgrund derer es zu einem eingeschränkten Zugriff auf deine Webseite kam.
Der wichtigste beider Bereiche ist der URL-Fehler Bericht, da du über diesen eine Auflistung spezifischer Fehlerquellen erhältst, die Google beim Crawlen deiner Webseite festgestellt hat. Im Bericht werden Desktop- und Smartphone-Daten getrennt voneinander aufgeführt.
Die beschriebene Zusammenfassung aller Crawling-Fehler findest du in der Search Console unter „Crawling“ >> „Crawling-Fehler“.
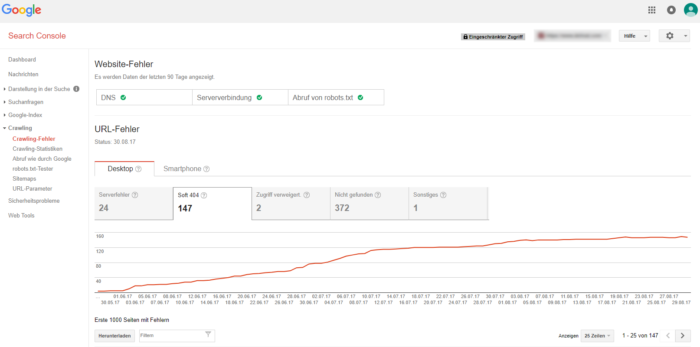
Crawling-Fehler-Typen bei Desktop und Smartphone: Serverfehler, Zugriff verweigert und andere Eskapaden
Google unterscheidet die Crawling-Fehler aktuell in sechs Kategorien. Für mobile Seiten werden noch weitere spezifische URL-Fehler ausgegeben. Im Folgenden sollen diese erläutert werden:
Serverfehler
Ursprung:
Diese Fehler entstehen, wenn der Googlebot keinen Zugriff auf die URL hatte oder die Webseite nicht verfügbar war. Auch eine Zeitüberschreitung, deren Ursache in einer falschen Konfiguration oder Überlastung des Servers liegen kann, ist ein möglicher Grund, dass der Googlebot die Anfrage abbrechen musste.
Priorität:
Serverfehler sind stets kritisch und sollten schnellstens behoben werden, da sie darauf hinweisen, dass es ein technisches Problem gibt, welches höchstwahrscheinlich auch Nutzer betrifft. Gern verschwinden diese Fehler aber auch ohne Zutun.
Zugriff verweigert
Ursprung:
Ein „Zugriff verweigert“ – Fehler entsteht, wenn dem Suchmaschinenbot der Zugriff auf eine Unterseite oder auch auf die ganze Webseite verwehrt wird. Für gewöhnlich entstehen solche Suchmaschinensperren durch Blockaden via robots.txt oder .htaccess. Werden diese Seiten dann beispielsweise mittels follow-Link referenziert, entsteht ein solcher Fehler.
Priorität:
Hier muss von Fall zu Fall entschieden werden. Es kann sein, dass die Blockade bestimmter URLs im Sinne des Webmasters ist und die Fehler getrost ignoriert werden können. Tauchen hier allerdings URLs auf, die eigentlich in den Index gehören, sollte schnell gehandelt werden. Gerade nach Änderungen an der robots.txt oder .htaccess sollte diese Kurve im Auge behalten werden. Hierbei helfen Funktionen wie „Abruf wie durch Google“ und der „robots.txt-Tester“ in der Search Console.
Nicht gefunden
Ursprung:
Diese Fehler entsprechen dem klassischen 404 Fehler. Er entsteht, wenn URLs (intern oder extern) verlinkt werden, welche keinen Inhalt aufweisen, die also nicht existieren und dem Crawler der Fehlercode 404 zurückgegeben wird. Oft entstehen diese Inhalte, wenn die Sitemap nicht regelmäßig aktualisiert wird, alte Inhalte auf der Webseite verlinkt werden oder Produkte wegfallen, die durch externe Seiten verlinkt wurden. Auch Rechtschreibfehler im Linkziel eines Hyperlinks sind häufig auftretende 404-Quellen. Zum Umgang mit diesen Fehlern folgt weiter unten ein ausführlicher Abschnitt.
Priorität:
Wie auch bei den „Zugriff verweigert“ Fehlern muss hier von Fall zu Fall entschieden werden. Dabei unterscheidet man z.B. nach Aktualität des aufgeführten Fehlers oder der Linkquelle. Je nach Fehlerquelle ändert sich die Priorität zur Behebung der Fehler.
Soft 404
Ursprung:
Soft 404 Fehler werden auch als falsche 404 Fehler bezeichnet und entstehen dann, wenn ein Inhalt offenbar nicht mehr verfügbar ist, aber dennoch kein 404 Fehler zurückgegeben wird, sondern der Nutzer z.B. auf die Startseite weitergeleitet wird. Dann erkennt Google, dass da irgendwas nicht stimmt und fragt sich, ob da nicht ein Fehler vertuscht wird.
Auf die Bearbeitung von Soft 404 Fehlern wird weiter unten im Blogartikel noch detaillierter eingegangen.
Priorität:
Die Fehlerbehebung sollte mit hoher Priorität bemessen werden, da sich Soft 404 Fehler negativ auf das Gesamt-Crawling der Webseite auswirken können. Hintergrund ist, dass der Googlebot ggf. zu viel Crawling-Budget in die nicht vorhandenen Seiten investiert und dadurch relevante URLs seltener besucht werden.
Die Behebung beschränkt sich hier zumeist auf die Erstellung einer korrekten 404 Seite und Weiterleitung der betroffenen Seiten auf diese oder wenn eine identische Seite vorhanden ist, eine 301 Weiterleitung auf die neue Seite. Ebenfalls möglich ist der Antwortcode 410. Diese Möglichkeit solltest du jedoch nur in Betracht ziehen, wenn feststeht, dass die Seite nie wieder wichtig ist, da 410 eine endgültige Entfernung bedeutet. Mit Anwendung der entsprechenden Maßnahmen sollten dann auch alle Soft 404s verschwinden. Aus diesem Grund solltest du dich dem einmaligen Aufwand stellen und die Fehler schnell beheben, bevor größerer Schaden entsteht.
Nicht gefolgt
Ursprung:
Google erklärt, dass Fehler dieser Klasse zugeordnet werden, insofern der Crawler glaubt, dass eine URL existiert, er diese aber nicht verfolgen, oder die Inhalte auf der URL nicht vollständig lesen kann. Ursachen hierfür können dynamische Parameter wie Session-IDs, Cookies oder die Verwendung von Flash-Elementen sein. Dadurch können z.B. dynamische URLs entstehen, die verlinkt sind, aber abhängig von einem Cookie (den der Crawler nicht hat) ihre Inhalte wechseln. Der Crawler ist dann der Meinung, dass er die Inhalte nicht abrufen kann und folgt der URL nicht.
Priorität:
Wichtiger als die Beseitigung der eigentlichen Fehler ist hier die Beseitigung der Ursache. Insofern tatsächlich dynamische URLs verwendet werden sollen oder die Inhalte der aufgeführten URLs bewusst so gewählt sind, so sollte man den Crawler lieber via robots.txt vorwarnen und ihm die Ressourcen sparen. Abhilfe schafft hier auch die Möglichkeit, entsprechende Parameter in der Serach Console zu hinterlegen und dem Googlebot mitzuteilen, wie er damit umgehen soll. Im besten Falle verhinderst du aber solche Situationen generell.
DNS-Fehler
Ursprung:
DNS-Fehler kommen zustande, wenn der Googlebot nicht mit dem DNS-Server kommunizieren konnte. Ursachen liegen hierbei in einem Server-Absturz oder Problemen mit dem DNS-Routing der Domain.
Priorität:
Laut Google wirken sich Warnungen oder Fehlermeldungen in Bezug auf DNS-Fehler nicht darauf aus, ob der Googlebot auf die Webseite zugreifen kann. Allerdings können sich genannte Probleme auf die Nutzererfahrung auswirken, weshalb eine Behebung der Fehler empfohlen wird.
Fehlerhafte Weiterleitungen (Smartphone)
Ursprung:
Wenn ein Webseitenbetreiber eine separate mobile Seite zur Verfügung stellt, kann es unter Umständen zu fehlerhaften Weiterleitungen kommen. Dieses Problem entsteht, wenn der Smartphone-Nutzer zu einer nicht seiner Suchanfrage entsprechenden URL weitergeleitet wird, z.B. einer Weiterleitung jeglicher Desktop-Seiten auf die mobile Startseite. Der Fehler findet sich dann unter dem Bericht URL-Fehler im Tab „Smartphone“.
Priorität:
Da dieses Problem die mobile Nutzererfahrung erheblich beeinträchtigt, sollten fehlerhafte Weiterleitungen unbedingt korrigiert bzw. vermieden werden.
Blockierte URLs für Smartphones
Ursprung:
Dieser Fehler entsteht, wenn die URL für den Smartphone-Googlebot in der robots.txt vom Crawling ausgeschlossen wurde. Es handelt sich nicht zwingend um einen Smartphone-spezifischen Fehler, da die Blockierung ebenfalls für die Desktop-Variante auftreten kann.
Priorität:
Sollte die Blockierung allerdings dazu führen, dass entsprechende Seiten nicht in den mobilen Suchergebnissen erscheinen, da kein Crawling möglich war, so sollte die robotx.txt überprüft und ggf. korrigiert werden.
Flash-Inhalte
Ursprung:
Unter diesem Fehler werden alle URLs zusammengefasst, deren Inhalt größtenteils im Flash-Format gerendert wird. Browser mobiler Endgeräte haben mit deren Verarbeitung Probleme, weil Flash von iOS und Android-Versionen ab 4.1 nicht unterstützt wird.
Priorität:
Mit Flash-Inhalten sollte für Mobilgeräte möglichst nicht mehr gearbeitet werden. Zur Behebung solcher Probleme empfiehlt Google die Verwendung eines responsiven Designs. Ferner solltest du sicherstellen, dass der Googlebot auf alle wichtigen Dateien wie Bilder, CSS und JavaScript zugreifen kann und diese nicht durch die robots.txt blockiert sind.
Nachdem du die typischsten Fehler nun kennst, erfährst du in den folgenden Abschnitten wie im Speziellen 404 und Soft 404 Fehler bearbeitet werden sollten.
Bearbeitung von 404 Fehlern aus der Search Console
Die 404 Fehler entstehen wie einführend erwähnt immer dann, wenn URLs angesteuert werden, die nicht existieren. Während der Nutzer diese direkt durch Falscheingabe einer URL erzeugen kann, stößt ein Suchmaschinenbot nur darauf, wenn er einen Hinweis bekommt. Hinweis bedeutet in diesem Falle, dass er einen Link auf die nicht existierende URL findet und diesem folgt. Durch einen Headercode wird dem Crawler mitgeteilt, dass unter der aufgerufenen URL keine Inhalte hinterlegt wurden. Wird kein 404 Status Code ausgeliefert, so entsteht in den meisten Fällen ein Soft 404 Fehler.
Wie gehst du am besten vor, wenn im Search Console Account „Nicht gefunden“-Fehler auftauchen?
Als erstes solltest du dir die betroffenen URLs herunterladen und in einer Excel-Tabelle öffnen (siehe folgender Screenshot). Google gibt dabei die 1.000 wichtigsten URL-Fehler je Kategorie aus. Im nächsten Schritt solltest du mithilfe eines Crawling-Tools (z.B. Screaming Frog, List-Mode nutzen) überprüfen, ob die aufgelisteten URLs immer noch einen 404 Status Code aufweisen. An dieser Stelle lassen sich bereits einige URLs aussortieren, die inzwischen weitergeleitet wurden oder wieder erreichbar (Status Code 200) sind. Diese kannst du z.B. in deiner Excel grün kennzeichnen und bereits als korrigiert in der Search Console markieren:
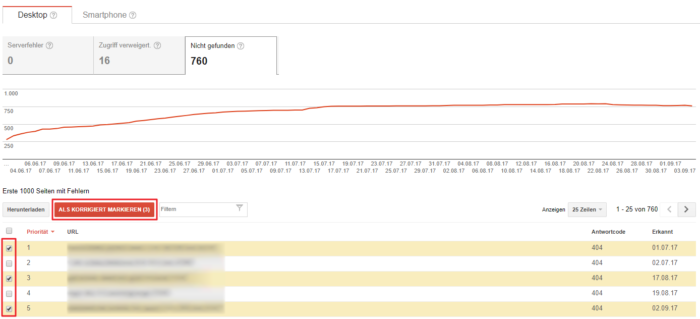
Da es in vielen Fällen zu aufwändig ist, jede verbleibende URL einzeln zu prüfen, muss versucht werden, die URLs zu gruppieren, so dass alle URLs einer Gruppe vermutlich die gleiche Fehlerursache oder zumindest -struktur haben. Die URLs einer Gruppe sollten so homogen wie möglich sein.
Beim durchscrollen der Liste lassen sich gegebenenfalls schon Muster erkennen und eine gewisse Clusterung finden. Entspringen zum Beispiel alle (oder zumindest ein Großteil) der URLs einem bestimmten Verzeichnis, so kann man das Problem schon ein wenig eingrenzen.
- Wurden z.B. in jenem Verzeichnis kürzlich Änderungen an der URL Struktur vorgenommen?
- Könnten die Zugriffsrechte des Verzeichnisses verändert worden sein?
- Sind die angezeigten URLs veraltet?
Vermutlich wirst du nicht alle aufgeführten URLs in ein und dasselbe Cluster einordnen können, da die Ursachen meist vielfältiger sind.
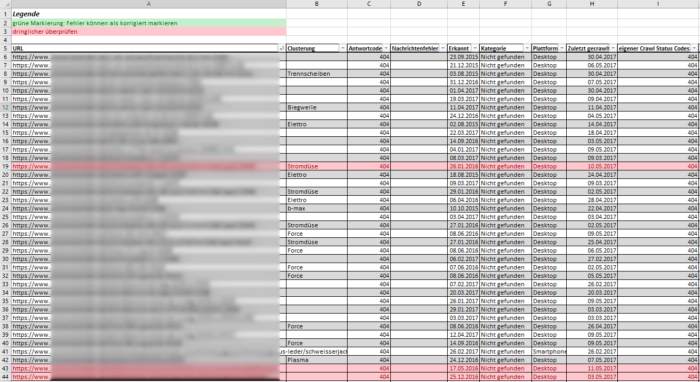
Hast du die URLs in Gruppen aufgeteilt, so musst du nun die einzelnen Ursachen finden. Diese findest du z.B. in der Linkquelle. Dazu prüfst du die URL, von der die nicht vorhandene URL verlinkt wird. Google gibt glücklicherweise Aufschluss darüber: um sich die Quelle anzeigen zu lassen, klickst du auf eine der aufgeführten URLs in den Search Console und wechselst im Popup-Fenster zum Reiter „Verlinkt über“. Dort findest du eine Liste aller Linkquellen für die „Problem-URL“:
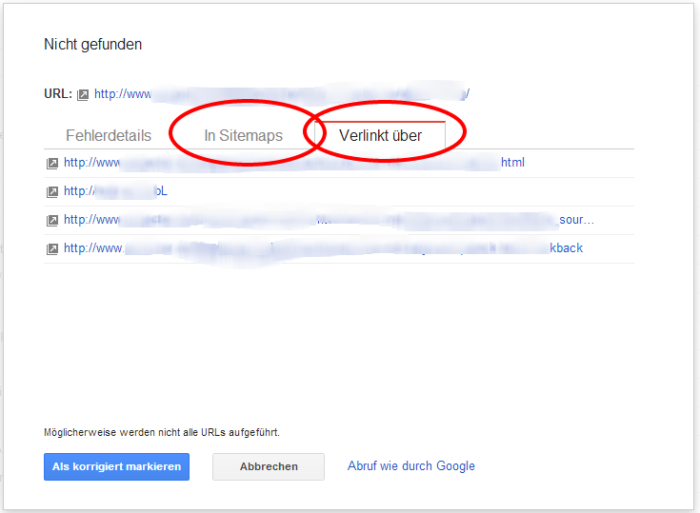
Hier gilt es nun zu prüfen:
- Existieren die angeblichen Linkquellen überhaupt?
- Ist der angebliche Link überhaupt auf der Seite eingebunden?
- Gibt es nur interne Linkquellen oder wurde auch von externen Seiten verlinkt?
All diese Sachen müssen geprüft werden, um die Glaubwürdigkeit des Fehlers zu prüfen. Auch an dieser Stelle ergeben sich gern noch einmal Muster. Es ist beispielsweise denkbar, dass alle aufgeführten 404-Seiten von der Sitemap aus verlinkt wurden oder von einer alten URL Struktur.
Die Beseitigung des Problems muss dann individuell angegangen werden, je nach Fehlerquelle und vor allem nach Glaubhaftigkeit der Fehlerangabe.
Google neigt dazu, bereits längst behobene 404 Fehler lange in der Search Console aufzuführen. Du kannst, um einen gewissen Filtereffekt zu erreichen, auch alle aufgeführten Fehler bereits zu Beginn deiner Analyse als korrigiert markieren. Dann sind für etwa 24h keine 404 Fehler aufgeführt, diese kommen aber nach und nach wieder zurück, wenn sie denn tatsächlich gerechtfertigt sind. Diese Methode kann im Vorfeld Übersicht verschaffen, ist allerdings nicht unbedingt im Sinne von Google. Allerdings versichert Google auch, dass es keine Auswirkungen auf Rankings hat, wenn du so vorgehst. Es wird lediglich gewarnt, dass die Fehler wieder auftreten, wenn sie nicht behoben wurden.
Sollte sich ein tatsächlicher Fehler auftun, so muss dieser natürlich korrigiert werden. Dies passiert entweder über die Einrichtung einer 301-Weiterleitung auf eine der ursprünglichen Seite thematisch möglichst ähnlichen Seite oder, wenn möglich, durch die Anpassung der Linkquelle (Vertipper korrigieren, neues Linkziel wählen, Sitemap aktualisieren …). 301 Weiterleitungen auf unpassende Seiten werden von Google ähnlich einer 404 Seite behandelt, das Weiterleitungsziel sollte also inhaltlich sehr nahe an der Ursprungseite sein.
Wichtig: Es müssen nicht alle 404 Fehler korrigiert werden. Es ist durchaus natürlich für eine Webseite (besonders für größere Seiten mit 500+ URLs) einzelne 404 Angaben in der Search Console zu beherbergen. Das kann z.B. passieren, wenn Produkte aus dem Sortiment genommen werden. Unter Umständen kannst du durch die Behebung der Fehler viel Linkpower reaktivieren. Du solltest diese Unterseiten dann definitiv weiterleiten, um die gesamte Linkpower der externen Domain zu nutzen.
Bearbeitung von Soft 404 Fehlern in der Search Console
Oben wurde bereits erklärt, wie die sogenannten Soft 404s entstehen. Da die Fehlerquellen von Soft 404s identisch sind mit denen „normaler“ 404 Fehler, ist auch die Vorgehensweise die gleiche:
- Muster erkennen
- Cluster erstellen
- für jedes Cluster die Ursache/n finden
- Ursachen beheben
- Beobachten
Du kannst aber auch noch eine zusätzliche Maßnahme ergreifen, um Soft 404s von vornherein auszuschließen. Die Fehler entstehen dann, wenn der Nutzer eigentlich auf einer 404 Seite landen sollte, da der Inhalt nicht erreichbar ist. Stattdessen wird er z.B. standardmäßig auf die Startseite umgeleitet und ein 404 Code wird nicht zurückgegeben. Da für Google in diesem Falle der Inhalt der Startseite unter vielen verschiedenen Inhalten erreichbar ist, wird die Suchmaschine stutzig und führt einen Soft 404 auf.
Die simple Schlussfolgerung lautet: Es sollte eine 404 Seite hinterlegt werden. Diese sollte im besten Fall liebevoll gestaltet sein und sinnvolle Links aufweisen. Dieser Schritt sollte in den meisten Fällen das Auftreten dieser Fehlerart unterbinden.
Fazit
Behältst du die Statistiken, die uns Google zur Verfügung stellt, stets im Auge, so kommt es nicht dazu, dass sich Fehler anhäufen und du gegen Windmühlen kämpfst. Kommst du dennoch zu diesem Punkt, so solltest du strukturiert vorgehen und die Probleme nach und nach mittels der beschriebenen Vorgehensweise beheben. Wie aber schon oben angebracht, wirst du in den seltensten Fällen einen Search Console Account einer halbwegs komplexen Seite finden, in dem null Crawling-Fehler zu finden sind.



DANKE!
Durch diesen Artikel habe ich endlich einige Zusammenhänge verstanden und konnte ein paar Fehler verstehen, eingrenzen und beseitigen. Juhu,…endlich mal schnell gefunden, was ich gesucht hatte…
Vielen Dank
Die Spielerin
Hallo Spielerin,
vielen Dank für dein Feedback zum Artikel.
Viele Grüße
Christin
Wow 😀
Vielen Dank für das aufschlüsseln der einzelnen Ursachen. gerade für Anfänger wie mich ist es oftmals schwer diese ganzen neuen Informationen bzgl. der Google Console zu verstehen und diese Übersicht hilft dadurch natürlich sehr!
Liebe Grüße
Thomas
Hallo Thomas,
das freut mich, dass wir dir weiterhelfen konnten.
Vielen Dank für deine positive Rückmeldung.
Liebe Grüße
Christin
Vielen Dank für diesen Artikel!
Eine Frage:
Gibt es die Möglichkeit die Liste aller Linkquellen passend zu der entsprechenden URL zu exportieren?
Vielen dank im Voraus!
Hallo Britta,
im Search Console Interface ist es leider nicht möglich. Über die Google Search Console API hast du jedoch die Möglichkeit, die eingehenden Verweise zur fehlerhaften URL zu exportieren.
Ich hoffe, das hilft dir weiter.
Liebe Grüße
Christin
Meine schnelle Rettung habe ich hier gefunden – ein toller und sehr übersichtlicher Beitrag (ich LIEBE Screenshots in anleitungen). Nach der SSL Verschlüsselung habe ich in der Search Console haufenweise Fehlermeldungen bekommen. U.a. toller Tip, das mit Screaming frog zu prüfen. DANKE!
Wir hatten das Problem, dass nach einem Serverumzug die Dateirechte für robots.txt unbemerkt so gesetzt waren, dass von Außen nicht darauf zugegriffen werden konnte. Die Datei lag schon ordnungsgemäß im Hauptverzeichnis, durfte aber nicht gelesen werden. Eventuell könnte man auf diesen Umstand als Fehlerquelle ebenfalls noch hinweisen.
Hallo,
vielen Dank für deine Anregung. Wir werden es gleich an den Autor des Artikels weiterleiten.
Grüße,
das Projecter Team
Hallo,
vielen Dank für deinen Input. Ich prüfe bei Gelegenheit meinen Artikel noch einmal und schaue, ob ich deinen Hinweis an einer passenden Stelle unterbringen kann.
Viele Grüße
Christin
Was auch noch ein sehr nerviges Problem mit der Indexabdeckung sein kann ist die falsche Interpretation des Googlebot bei der kanonischen URL.
Diese hat mich bei einem 2-sprachigem Blog erwischt.
Google sagt also das (obwohl die jeweilige Sprache eines Posts immer eine eigenständige URL hat) es sich um Duplicate Content handelt, und hat (ausgerechnet) alle deutschen Beiträge aus dem Index geworfen.
Das tragische ist das es Wochen und sogar Monate dauern kann bis das alles wieder im Lot ist und die Seiten im Index sind.
Hallo Michael,
vielen Dank, dass du deine Erfahrungen mit uns teilst. Hast du bei deinem Blog mit hreflang-Tags gearbeitet und Google hat die URLs trotzdem als Duplicate Content gewertet?
Viele Grüße
Christin
Ja, ich habe eigentlich alles richtig gemacht, und auch jeweils den canonical Tag für jede Seite im Head eingefügt.
Es ging ja auch alles monatelang gut, und der Traffic ist jeden Monat um bis zu 10% gestiegen.
Aber dann auf einmal war Schluss mit lustig, und alle deutschen Beiträge waren aus dem Index.
Das Problem habe ich aber auch nicht alleine so wie ich es in dem Hilfeforum der Google Search Console gesehen habe.
So langsam scheint Google aber zu kapieren das da was nicht richtig läuft, und so nach und nach kommen die deutschen Beiträge (und damit auch der Traffic) wieder zurück.
Ich bin nur froh das ich bei den Beiträgen die jetzt wieder indexiert sind mein altes Ranking behalten habe, und mich nicht erneut hocharbeiten muss.
Denn das kann ja erfahrungsgemäß auch ein langwieriger Prozess sein.
Google selbst rät derzeit auch dazu den Angaben die in der neuen Search Console gemacht werden nicht in allen belangen auf die Goldwaage zu legen, und überstürzt Änderungen an den Seiten vorzunehmen.
Ich denke das ich jetzt einfach nur noch abwarten kann bis sich das ganze wieder gefangen hat, da ich von meiner Seite aus nichts weiter tun kann.
Sehr interessanter Artikel. Wir nutzen die gesamte Google Palette seit Jahren für unser Online-Shop. Dies ist als Unternehmer mit nationalem Shopping Versand unerlässlich. Aber als Tipp aus unserer Erfahrung ist folgender: Prüft bitte in eurem Shop die Lagerverwaltung. Wie das gemeint ist? Ganz einfach: Wir hatten mal extrem schlechte Rankings und haben festgestellt, dass einige Artikel vom Bestand her negativ waren, also quasi nicht an Lager, sodass unser System diese deaktiviert hat. Es entstand ein toter Link, Google fand das heraus und spickte uns aus den organischen SERPs. Daher bitte die Lagerbestände für KMU’s genügend angeben und bei grossen Unternehmen die richtigen Mengen hinterlegen und nie Stockouts haben. Eine andere Variante wäre es natürlich die Deaktivierung von Produkten im Online-Shop bei negtiver Menge zu verhindern, stattdessen den Vermerk: aktuell ausverkauft angeben.
Liebe Grüsse aus der Schweiz
Angelo