Duplicate Content in Online Shops beseitigen – Teil 1 – Technischer Duplicate Content
Was ist Duplicate Content?
Duplicate Content gehört wohl zu den Themen, mit denen jeder SEO schon einmal im kleineren oder größeren Umfang zu kämpfen hatte. Schlagen wir das Thema direkt bei Google nach, heißt es dort, dass es sich bei Duplicate Content im Allgemeinem um „umfangreiche Contentblöcke, die anderem Content auf derselben oder einer anderen Domain entsprechen oder auffällig ähneln“ handelt. Weiter heißt es außerdem: „Google ist sehr darum bemüht, Seiten mit unterschiedlichen Informationen zu indizieren und anzuzeigen. […] In den seltenen Fällen, in denen wir annehmen müssen, dass duplizierter Content mit der Absicht angezeigt wird, das Ranking zu manipulieren oder unsere Nutzer zu täuschen, nehmen wir die entsprechenden Korrekturen am Index und Ranking der betreffenden Websites vor“. Zack! Und schon habe ich Inhalte von Google dupliziert! Aber aus Google-Sicht ist dies natürlich durchaus eine logische Vorgehensweise, bieten duplizierte Inhalte ja für den Nutzer in der Regel wenig bis keinen Mehrwert. Für Webseitenbetreiber und SEOs gilt es deshalb natürlich duplizierte Inhalte weitgehend zu vermeiden um nicht Opfer der angesprochenen „Korrekturen“ (beispielsweise Rankingherabstufung oder Deindexierung der betroffenen Seite) zu werden.
Wo ist jetzt genau das Problem?
Suchmaschinen indizieren keine Websites, sie indizieren URLs. Sollten nun aufgrund technischer oder redaktioneller Schwächen auf einer Seite dieselben oder sehr stark ähnliche Inhalte auf mehreren Seiten auffindbar sein, kann die Suchmaschine diese Inhalte nicht mehr eindeutig referenzieren. Was war zuerst da? Diese oder jene Seite? Wer hat hier warum bei wem abgeschrieben? Die Folge sind in den allermeisten Fällen Rankingprobleme in verschiedenen Ausmaßen. Dies kann insbesondere für Online Shops zu weniger Traffic und Umsatz führen.
Man kann ganz allgemein zwischen internem (sich auf der eigenen Seite befindlichen) und externem (sich also außerhalb der Seite befindlichem) Duplicate Content unterscheiden. In dieser Beitragsreihe möchten wir uns gerne dem Thema interner Duplicate Content annehmen und Hinweise geben, wo die häufigsten Gefahren für Online Shops bei diesem Thema lauern und wie diese am besten vermieden werden können.
Parameter-URLs
Bei Erzeugung dynamischer URLs durch die Verwendung von Parametern kann es vorkommen, dass gleiche Inhalte unter mehreren URLs erreichbar werden. Wie eingangs erwähnt verwirrt dies Suchmaschinen und die Signale, die die vielen URLs zu den Inhalten senden werden abgeschwächt.
Typische Parameter-URLs bei Online Shops ergeben sich z.B. aus der „Sortieren nach:“-Funktion (?order=price) oder der Filter-Navigation (Farbe, Marke, Preis, Ausführung etc.). Ein Beispiel:
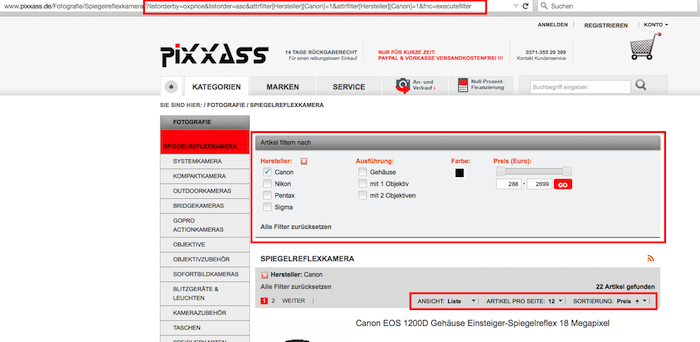
Hier sehen wir uns eine Auswahl von Spiegelreflexkameras des Herstellers Canon an, die ich mir nach Preis aufsteigend sortiert anzeigen lasse. Wie man in der Adresszeile sehen kann, werden dabei der URL verschiedene Parameter angehängt. Je nach Angebot und ausgewählten Filtern kann es nun dazu kommen, dass eine andere Kombination von Filtern die exakt gleichen Seiteninhalte erstellt wie diese. Die inhaltlichen Unterschiede zwischen den so dynamisch erzeugten URLs sind marginal bis nicht vorhanden. Wir sind also bei Nichtbeachtung mitten im Problemfeld Duplicate Content.
Eine Möglichkeit solche duplizierten Inhalte durch Parameter zu vermeiden ist der Einsatz sogenannter Canonical Tags, mit denen auf eine eindeutige Standardressource verwiesen werden kann. Kommt der Google Bot dann auf die gefilterte URL, signalisiert das Canonical Tag, dass es Seiten mit identischen/ähnlichen Inhalten gibt und bittet ihn, nur die Standardversion in den Index aufzunehmen.
Die Syntax für unser Beispiel sieht folgendermaßen aus:
<link rel="canonical" href="http://www.pixxass.de/Fotografie/Spiegelreflexkamera/"/>
Dieses Element wird im <head> Bereich des Quellcodes platziert und verweist so auf die Standardseite.
Die folgende Tabelle illustriert das Prinzip von URL und Canonical URL:
| URL Typ | Sichtbare URL | Canonical URL |
| Standard | http://www.pixxass.de/Fotografie/Objektive/ | http://www.pixxass.de/Fotografie/Objektive/ |
| URL mit sortierter Ansicht | http://www.pixxass.de/Fotografie/Objektive/?listorderby=oxprice&listorder=desc | http://www.pixxass.de/Fotografie/Objektive/ |
| URL mit Produktliste | http://www.pixxass.de/Fotografie/Objektive/?ldtype=line | http://www.pixxass.de/Fotografie/Objektive/ |
Außerdem möglich: Man kann auch darüber nachdenken, die URLs mit Parametern vom Crawling gänzlich auszuschließen. Eine Einstellung zum Ignorieren der URL-Parameter findet man auch direkt in der Google Search Console bzw. den Bing Webmaster Tools.
Auch über Regeln in der robots.txt kann dem Duplicate Content durch Crawlingverbot entgegengetreten werden. Hier zwei Beispiele:
Disallow: *?listorderby=*
Disallow: *?ldtype=*
Die robots.txt verhindert dabei nicht die Indexierung der URL. Da der Googlebot die Seite aber nicht laden darf, sieht er aber auch die doppelten Inhalte nicht.
Wenn jede URL mit Parametern für den Crawl gesperrt werden soll, kommt die Regel
Disallow: *?*.* zum Einsatz.
Vorteil der Benutzung von robots.txt-Regeln ist, dass damit auch wertvolles Crawl-Budget der Suchmaschine eingespart wird und sich die Suchmaschine voll und ganz auf die relevanten Seiten konzentrieren kann.
Session Ids
Sollte man Session IDs in der URL zur Nachverfolgung von Nutzerverhalten verwenden, kann mit diesen genauso wie mit Parametern verfahren werden. Es bieten sich am ehesten Canonical Tags an. Wer Cookies für das Nutzertracking benutzt, dem stellt sich dieses Problem allerdings gar nicht.
Interne Suche
Bei großen Online-Shops ist eine interne Suche für den Nutzer sehr hilfreich. Allerdings sind die Ergebnisseiten für die Suchmaschine nicht immer relevant und bergen ebenfalls die Gefahr duplizierter Inhalte. Die Indexierung der internen Suche ist ein sehr geläufiges Problem bei Online Shops. Viele Shopsysteme haben interne Suchergebnisse standardmäßig nicht auf „noindex, follow“ gesetzt, so dass hier der Webmaster ggf. nachbessern muss.
Produkt-URL-Pfade
Für Shopbetreiber und Nutzer kann es praktisch sein, wenn ein und dasselbe Produkt in mehreren Shop-Kategorien gelistet ist. Hier sollte rechtzeitig über das URL Design der Produktseiten nachgedacht werden. Oft kommt es vor, dass der Kategoriepfad dann auch auf Produktseiten Bestandteil der URL ist. Wenn Produkte dann in mehreren Kategorien auftauchen, entstehen mehrere URLs mit identischen Inhalten: Duplicate Content. Da für Shops aber insbesondere die Produktseiten für Rankings und Käufe relevant sind, sollten hier keine Potenziale verschwendet werden!
Es ist daher empfehlenswert die Produkt-URLs immer ohne die dazugehörige Kategorie (www.beispielshop.de/beispielprodukt) anzuzeigen, um diese Probleme zu vermeiden. Die Verwendung von Canonical Tags wäre aber auch hier eine Möglichkeit.
WWW und Groß- und Kleinschreibung
Auch http://www.beispielshop.de und http://beispielshop.de sind aus Suchmaschinensicht zwei unterschiedliche Adressen. Es ist also wichtig, sich für eine Schreibweise zu entscheiden und die andere Schreibweise mittels einer permanenten 301-Weiterleitung auf diese zu verweisen. Gleiches gilt für Groß- und Kleinschreibung. Auch hier ist es wichtig sich für eine Schreibweise zu entscheiden und z.B. mittels regelbasierten URL Umschreibungen alle Großbuchstaben in Kleinbuchstaben zu wandeln und dabei den Status Code 301 zurückzugeben.
Trailing Slashes
Ganz ähnlich verhält es sich auch mit Trailing Slashes. Auch die Seite www.beispielshop.de/kategorie ist für eine Suchmaschine eine andere Adresse als www.beispielshop.de/kategorie/. Diese Probleme lassen sich am besten mit der Nutzung von Canonical Tags oder der 301-Weiterleitung der einen Version auf die andere beheben. Hierbei ist die zweite Variante zu bevorzugen, da Canonical Tags bei einer möglichen externen Verlinkung der „falschen“ URL einen Dämpfungsfaktor in ihrer Linkwirkung erzeugen würden. Und niemand von uns möchte Linkpower verschwenden. 😉
Warenkörbe
Ebenfalls sollten Warenkorb-URLs aus dem Suchindex ausgeschlossen werden. Diese sind für die Suchmaschine irrelevant. Diese Seiten sollten auf „noindex, nofollow“ gesetzt werden. Der Ausschluss erfolgt hierbei über ein Meta Tag im Quelltext einer Website im <head>Bereich:
<meta name="robots" content="noindex,nofollow" />
Die meisten Shopsysteme verwenden für die Warenkorb-Seiten eindeutige URL-Bestandteile wie basket, cart oder warenkorb. Über diese Bestandteile können schnell Ausschlussregeln formuliert werden.
Kundenbewertungen
Oft werden alle Kundenbewertungen zu einem Produkt auf einer gesonderten Seite gesammelt aber auch einige Kundenbewertungen auf den Produktseiten selbst angezeigt. Auf diese Weise kann Duplicate Content entstehen. Diesem Problem begegnet man ebenfalls am besten, indem man diese Bewertungsseiten mit Canonicals versieht.
Fazit
Duplicate Content kann bei Online Shops auf verschiedenen Wegen entstehen. Die Behebung der hier beschriebenen eher technischen Probleme hält sich in den meisten Fällen im Rahmen und sollte recht schnell umgesetzt werden können. Schwieriger sieht es da mit Duplicate Content Problemen aus, die auf redaktionellem oder externem Wege entstehen. Auch für das Aufspüren von Duplicate Content gibt es verschiedene Tools und Möglichkeiten. Hierzu gibt es dann demnächst noch einmal gesonderte Beiträge.
Übrigens, die zu Beginn des Artikels verwendeten Google-Zitate sollten erfüllen nicht wirklich die Kriterien von Duplicate Content. Die Einbettung von Zitaten bringt euch Lesern schließlich einen Mehrwert und die Quelle ist klar benannt. 😉




[…] Duplicate Content in Online Shops beseitigen – Teil 1 – Technischer Duplicate Content […]
[…] zu Rankingabstufungen und sogar zur Deindexierung der betroffenen Seiten führen. Im ersten Teil dieser Serie wurden die technischen Quellen für doppelte Inhalte vorgestellt. Der zweite Teil […]
[…] erzeugten Filter-URLs umgegangen werden soll. Die Gefahr ist groß, dass durch Filteroptionen Duplicate Content entsteht. Das kann durch die Canonicals oder die Verwendung des Meta Robots Tags „noindex“ […]