Wie du Crawling-Fehler mit Hilfe der Search Console ausfindig machst und analysieren kannst
Googles Search Console liefert dir einen Überblick zu Crawling-Problemen auf deiner Website. Wir zeigen dir, welche Fehler und Probleme dir Google anzeigt und wie du diese am besten analysieren kannst.
Crawling-Fehler mit Hilfe der Google Search Console aufspüren
Unter Crawling-Fehler versteht man jegliche Probleme, denen der Suchmaschinen-Crawler beim Besuch einer Website begegnen kann. Ist es dem Crawler nicht gelungen, einen bestimmten Inhalt in den Index zu übermitteln, können hier verschiedene Probleme die Ursache sein. Ist eine Seite (temporär) nicht erreichbar? Wurde der Crawler ausgesperrt oder gab es einen Serverfehler? Diesen Problemen solltest du regelmäßig nachgehen, um sicherzugehen, dass Google und andere Suchmaschinen deine Website möglichst vollständig und korrekt erfassen. Ansonsten können wichtige Inhalte möglicherweise nie den Weg auf die Ergebnisseiten der Suchmaschinen finden.
Der einfachste und direkteste Weg, um eventuelle Crawling-Fehler ausfindig zu machen, ist der Einsatz der Google Search Console. Denn die Daten stammen direkt von Google und zeigen, wo der Suchmaschinen-Crawler auf ein Problem stieß. Dabei listet die Search Console genau auf, welche URLs betroffen sind und wann das Problem festgestellt wurde. Die einzige Beschränkung ist hierbei, dass Google pro Fehlerkategorie nur maximal 1.000 Einträge zeigt. Dies sollte in der Regel jedoch ausreichen, um Muster für bestimmte Fehler ausfindig zu machen und diese zu beheben.
Der Bericht „Abdeckung“: eventuelle Fehler schnell und einfach aufspüren
Zentrale Anlaufstelle für die Überprüfung der eigenen Website ist der Bericht Index > Abdeckung. Hier findest du alle URLs der Website, die Google bekannt sind. Der Bericht gliedert sich in vier Bereiche:
- Fehler: Diese Seiten konnten aus einem bestimmten Grund nicht indexiert werden. Auf die genauen Fehlerursachen gehen wir weiter unten detaillierter ein.
- Gültige Seiten mit Warnung: Diese Seiten wurden von Google indexiert. Dabei gab es jedoch Probleme und die Suchmaschine ist sich nicht sicher, ob eine Indexierung beabsichtigt ist.
- Gültige Seiten: Diese Seiten wurden erfolgreich von Google indexiert.
- Ausgeschlossen: Diese Seiten wurden von Google nicht indexiert. In der Regel ist dieser Ausschluss zwar beabsichtigt, aber auch diese Berichte solltest du dir regelmäßig anschauen. Je nach Seitentyp kann die Anzahl der ausgeschlossenen Seiten sehr hoch sein.
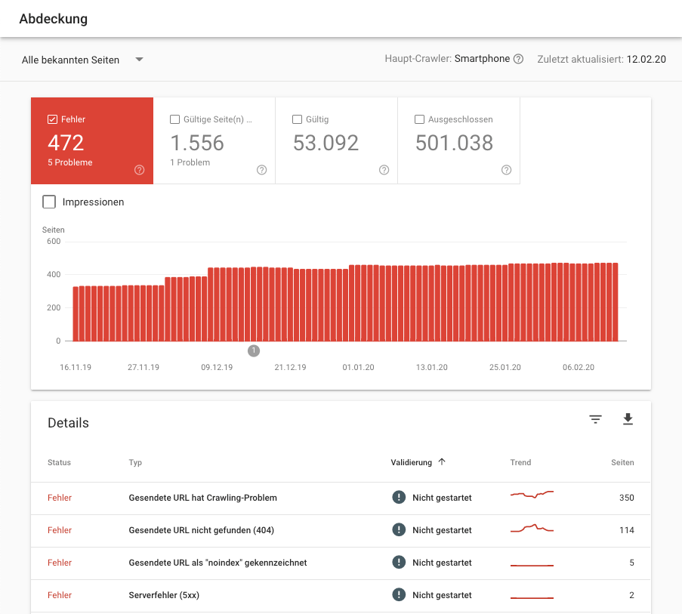
Für jeden Bericht führt die Search Console ein Diagramm für die letzten 90 Tage auf. Hierdurch lassen sich mögliche Fehlerursachen zeitlich eingrenzen, wenn sprunghaft an einem bestimmten Tag die Fehler anstiegen. Eine weitere wichtige Information versteckt sich oben rechts über den Berichten: Hier zeigt Google, welcher Crawler verwendet wurde. Ist die Seite bereits im Mobile First-Index, setzt Google für das Crawling seinen Googlebot für Smartphones ein. Das bedeutet, dass für die Indexierung nur der Inhalt relevant ist, der auf der mobilen Version der Website vorhanden ist.
Crawling-Fehler-Typen auf dem Desktop und dem Smartphone: Serverfehler, Zugriff verweigert und andere Eskapaden
Die folgende Übersicht zeigt dir, welche Fehler die Google Search Console ausgeben kann, woher diese Fehler stammen können und wie wichtig eine Fehlerbehebung ist:
| Fehler | Ursprung | Priorität |
| Serverfehler (5xx) | Dieser Fehler entsteht, wenn der Googlebot keinen Zugriff auf die URL oder Website hatte. Dies kann daran liegen, dass die Website gerade nicht erreichbar oder der Server überlastet war und Google daher die Anfrage abbrechen musste. | Serverfehler sollten auf jeden Fall im Blick behalten werden. Wenn Google Inhalte nicht aufrufen kann, weil die Website nicht erreichbar ist, sendet dies schlechte Signale an Google. Oft sind es jedoch nur temporäre Probleme. |
| Weiterleitungsfehler | Die Weiterleitung der URL funktioniert nicht, weil entweder die Weiterleitungskette defekt ist oder eine Weiterleitungsschleife existiert. | Die URL und alle mit ihr verbundenen Weiterleitungen sollten überprüft werden, da hier ein Fehler vorliegt, der nicht nur Google, sondern auch Nutzer betrifft und das Aufrufen der Zielseite verhindert. |
| Gesendete URL durch robots.txt blockiert | Hierbei handelt es sich um eine URL, die Google zwar indexieren soll (weil sie zum Beispiel in der Sitemap hinterlegt ist), die jedoch durch die robots.txt für Google blockiert wird. | Hier muss von Fall zu Fall entschieden werden, ob Handlungsbedarf besteht. Es kann durchaus sein, dass der Webmaster eine Seite nicht indexieren lassen möchte und diese durch eine robots.txt sperrt. Diese Seiten sollten dann beispielsweise jedoch nicht in der Sitemap aufgeführt sein. |
| Gesendete URL ist ein Soft 404-Fehler | Dies sind URLs, die den Hinweis zurückgeben, dass die Seite nicht existiert. Gleichzeitig wird jedoch ein gültiger 200-Statuscode (Seite erreichbar) gesendet. Google wertet eine Seite auch als Soft 404-Fehler, wenn es sich um eine Weiterleitung handelt, die thematisch nicht zur ursprünglichen Seite passt. | Solche Fehler verwirren Google und sollten daher mit hoher Priorität behandelt werden. Die betroffenen URLs sollten überprüft und ggf. auf einen 4xx-Statuscode geändert werden. |
| Gesendete URL gibt nicht autorisierte Anforderung (401) zurück | Der Abruf der URL ist mit einem Passwortschutz versehen, der zum Beispiel durch eine .htaccess-Datei festgelegt wurde. | Es sollte überprüft werden, ob der Passwortschutz für diese URL gewollt ist. Soll Google diese Seite indexieren, muss sie öffentlich abrufbar sein. |
| Gesendete URL nicht gefunden (404) | Die Seite ist nicht mehr verfügbar und gibt einen 404-Statuscode zurück. Dies kann passieren, wenn Inhalte entfernt werden, jedoch noch Links zu diesen Inhalten bestehen. | Hier muss von Fall zu Fall unterschieden werden. Sollte die Seite eigentlich erreichbar sein, so sollte der Ursprung des 404-Fehlers überprüft werden. Je älter der Fehler oder die Linkquelle zur betroffenen URL, desto geringer ist die Priorität zur Behebung des Fehlers. |
| Gesendete URL hat Crawling-Problem | Die Seite wurde zur Indexierung eingereicht, aber Google hat ein Problem damit, die Seite zu indexieren. Die Ursachen können dafür vielfältig sein und Google benennt sie nicht näher. | Diese Fehler sollten unbedingt genauer untersucht werden. Du solltest versuchen, die Ursache des Problems einzugrenzen. Da Google den Fehler nicht näher beschreibt, sind hier viele Ursachen möglich. |
So kannst du die 404-Fehler analysieren
Wir schauen uns beispielhaft die vorhandenen 404-Fehler genauer an und überprüfen diese. In dem Beispielprojekt gibt es 114 betroffene URLs. Klickst du auf die Fehlermeldung in der Abdeckungs-Übersicht, werden dir die entsprechenden URLs angezeigt. Zudem sehen wir hier auch die Entwicklung der Fehler:
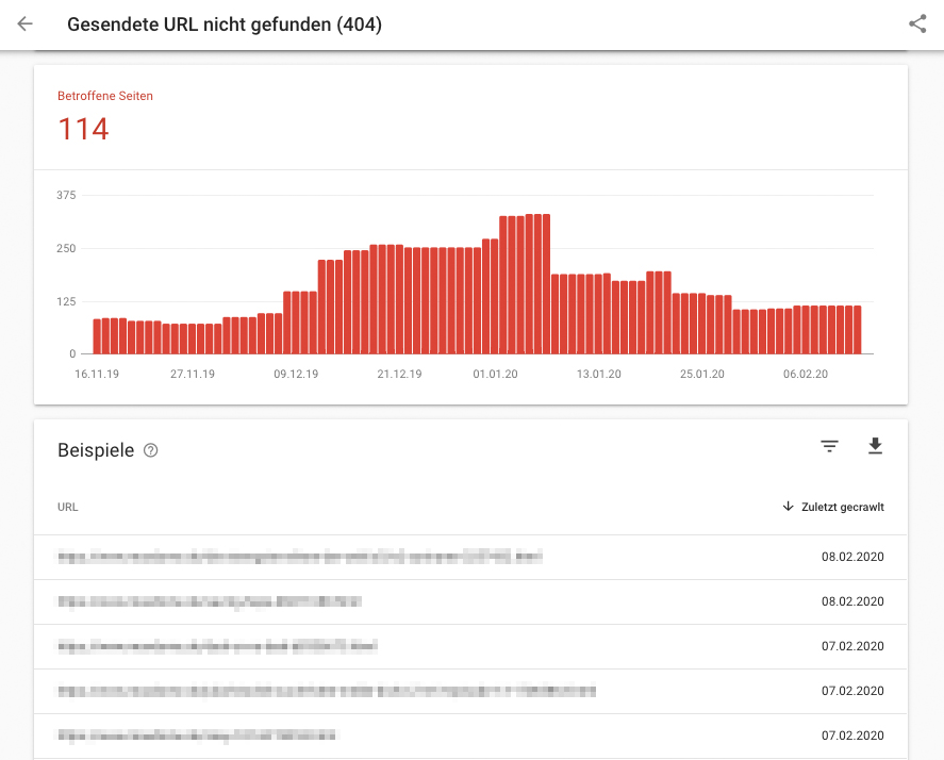
Zunächst solltest du überprüfen, ob die Fehler noch aktuell sind. Google überprüft nicht jeden Tag jede URL. Es kann also sein, dass die tatsächliche Anzahl der aktuellen 404-Fehler deutlich geringer ist. Du kannst dir betroffenen URLs durch das Download-Icon oben rechts als CSV-Datei herunterladen. Die URLs solltest du anschließend in einem Crawling Tool wie Screaming Frog überprüfen. Das Tool listet dir den Status der einzelnen URLs auf und du kannst dir die Übersicht zum Beispiel in Excel importieren:
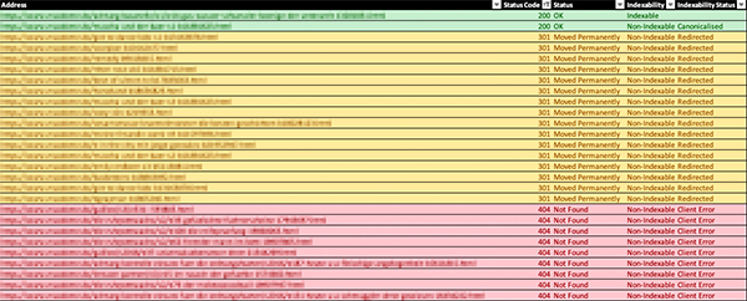
Zur besseren Übersicht kannst du dir die einzelnen Statuscodes farbig markieren. In unserem Fall gibt es zwei Seiten, die erreichbar sind (grün), einige URLs, die weitergeleitet wurden (gelb) und die restlichen noch aktiven 404-Fehler (rot). Insgesamt sind von den 114 angezeigten Fehlern nur noch 56 wirklich aktiv. Da bereits einige Weiterleitungen eingerichtet wurden, ist anzunehmen, dass sich Inhalte geändert haben und daher einige URLs nicht mehr gültig sind.
URL-Gruppierungen helfen beim Einschätzen von Problemen
Die übrigen URLs solltest du dir genauer anschauen und prüfen, ob sich diese gruppieren lassen:
- Sind es URLs in einem gleichen Verzeichnis? Hat sich womöglich die Verzeichnisstruktur geändert?
- Sind es URLs für ähnliche Seitentypen (zum Beispiel Kategorieseiten, Produktseiten oder Blogartikel)?
- Sind die URLs überhaupt noch relevant oder sehr veraltet?
Allein daran lassen sich schon Ursachen für mögliche Fehler ermitteln, denen du genauer auf den Grund gehen kannst. Ist noch immer offen, woher der Fehler kommen kann, hilft ein erneuter Blick in die Google Search Console.
Crawling-Probleme mit dem URL-Prüftool analysieren
Jegliche Crawling-Fehler kannst du am besten mit dem URL-Prüftool der Google Search Console analysieren. Das URL-Prüftool kannst du ganz einfach aufrufen, indem du oben in der Search Console die entsprechende URL eingibst. Dann zeigt dir Google alle relevanten Daten an, die beim letzten Crawl-Versuch zustande kamen.
Hier erfährst du zunächst, woher Google die URL bekannt ist. Stammt sie aus einer Sitemap oder verweist eine andere Seite darauf? Auch diese Daten sollten zunächst geprüft werden. Ist die URL wirklich noch in der Sitemap? Existiert die angegebene Seite mit der Verlinkung und ist darauf wirklich ein Link zur fehlerhaften Seite?
Hilfreich ist es, auch die Live-URL zu überprüfen. Dazu klickst du oben rechts auf den Button „Live-URL testen“. Dies ist vor allem ratsam, wenn du dir Crawling-Fehler anschaust, deren Ursache für das Problem nicht eindeutig ist. Google überprüft dann kurz den Live-Status der betroffenen Seite. Häufig lassen sich damit Fehler schon klären. Es kommt nicht selten vor, dass das Problem nicht mehr existiert und die Seite einen gültigen Statuscode ausweist. Oder die Search Console aktualisiert den Fehler und konkretisiert ihn.
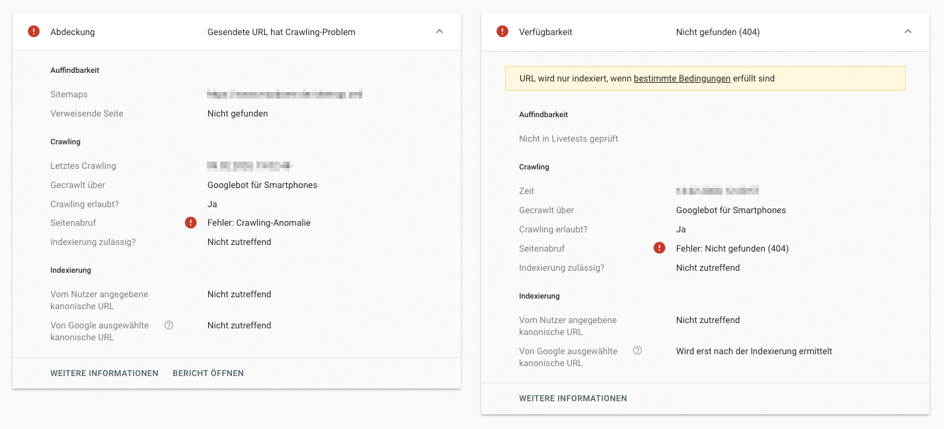
rechts die aktualisierten Fehler nach Abruf der Live-URL
Beim Analysieren einzelner URLs solltest du auch wieder nach Mustern Ausschau halten. Sind vielleicht alle angezeigten 404-Fehlerseiten in der Sitemap verlinkt? Dann sollte die Sitemap unbedingt aktualisiert werden, sodass sie nur gültige URLs enthält. Vielleicht gibt es noch eine veraltete Seite mit veralteten Links, die einfach nur angepasst werden muss. Die Fehlerursachen müssen hier individuell analysiert und behoben werden. Falsch geschriebene URLs sollten angepasst, nicht mehr existierende Seiten eventuell auf thematisch passende Seiten weitergeleitet werden. Hierbei gilt es zu beachten, dass Weiterleitungen auch wirklich hilfreich und sinnvoll sind. Sieht Google das neue Weiterleitungsziel nicht als thematisch passend an, so wird die Weiterleitung als Soft 404-Fehler angesehen.
Es müssen zudem nicht alle 404-Fehler behoben werden. Gerade für größere und ältere Seiten ist es völlig normal, dass bestimmte Inhalte nicht mehr existieren. Dies kann zum Beispiel passieren, wenn ein Onlineshop sein Sortiment aktualisiert. Die nicht mehr vorhandenen Produkte müssen dann nicht weitergeleitet werden.
Fazit: Prüfe die Daten und erkenne Muster
Die Google Search Console ist ein mächtiges Tool, um etwaige Probleme auf deiner Website festzustellen. Doch solltest du die angezeigten Daten stets überprüfen und schauen, ob die genannten Fehler überhaupt noch existieren oder wirklich relevant sind. Wirklich Zeit kannst du dir sparen, indem du die fehlerhaften URLs sinnvoll gruppierst und dann nach Mustern schaust. So musst du nicht jede einzelne URL individuell überprüfen. Denn gerade bei größeren Websites kann dies immens viel Zeit in Anspruch nehmen.
Über den Autor




